FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization
The recent amalgamation of transformer and convolutional designs has led to steady improvements in accuracy and efficiency of the models. In this work, we introduce FastViT, a hybrid vision transformer architecture that obtains the state-of-the-art latency
arxiv.org
GitHub - apple/ml-fastvit: This repository contains the official implementation of the research paper, "FastViT: A Fast Hybrid V
This repository contains the official implementation of the research paper, "FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization" ICCV 2023 - GitHub - apple/ml-f...
github.com
Abstract
- Trasnformer와 cnn 계열의 모델의 accuracy와 efficiency 꾸준히 개선되었다
- Hybrid vision transformer architecture인 FastViT는 state-of-the-art latency-accuracy trade-off를 달성하였다
- Structural reparameterization을 사용하여 skip connections 제거함으로서 메모리 액세스 비용을 낮춤
- Overparametrization와 large kernel convolutions을 사용하여 정확도를 높이고 이러한 선택이 지연 시간에 미치는 영향이 최소화됨을 경험적으로 보여줌
- 속도 : 현재 hybrid transformer architecture인 CMT보다 3.5배 빠르고, EfficientNet보다 4.9배 빠르고, 모바일 디바이스에서 ConvNeXt보다 1.9배 빠름
- 정확도 : 유사한 latency일 때 ImageNet에서 MobileOne보다 4.2% 좋은 Top-1 acc
- Image classification, detection, segmentation, 3D mesh regression 테스크에서 경쟁 아키텍쳐보다 우수한 성능
Structural reparameterization

RepVGG는 훈련 및 추론 시에 서로 다른 네트워크 형태를 사용하는 모델이다. 훈련 시에는 multi-branch(다중 분기) 모델을 사용하고, 추론 시에는 plain(평범한) 모델을 사용한다.
이렇게 서로 다른 모델을 사용함으로써 추론 시에는 더 가벼운 모델을 사용하여 속도를 높이고 메모리를 절약할 수 있다. 이를 가능하게 하기 위해 가중치(네트워크 내부의 학습 파라미터)를 재구성하거나 다른 방식으로 표현하는데, 이것을 "structural reparameterization(구조적 재매개화)"라고 부른다.
즉, 훈련 중에는 복잡한 네트워크 구조를 사용하여 모델을 훈련시키고, 추론 시에는 가중치를 재구성하여 더 간단한 구조로 바꾸어 사용한다.
Hybrid Transformer
주로 컨볼루션 신경망(CNN)과 트랜스포머 모델을 결합한 구조로 구성
Introduction
- Vision Transformers는 image classification, detection, segmentation과 같은 분야에서 sota를 달성해왔지만, computationally expensive하다
따라서 최근 연구 중 그런 단점을 보완하는 연구들이 나왔다- An attention free transformer
- Token pooling in vision transformers
- ...
- 최근의 hybrid architecture는 ViT 구조에서 cnn의 장점과 transformer의 장점을 합친 방향으로 가고 있다
- 저자의 목표는 sota latency-accuracy trade-off를 달성하는 모델이다 → 아마도 속도, 정확도 모두 좋은 모델을 제안하지만 그 사이에 trade off가 있는건 어쩔 수 없어서 이렇게 부르는 것 같음
- Hybrid 중 하나인 Metaformer의 아키텍처는 skip connections이 존재하는 token mixer와 또 다른 skip connections이 있는 FFN으로 구성되어있다.
하지만 skip connections은 memory access cost 때문에 상당한 오버헤드를 발생 - 이러한 skip connection 구조를 제거하여 비용을 아낄 수 있는 Reparameterization 기법인 RepMixer를 소개
따라서, 세 가지 주요 설계 원칙을 기반으로 하는 FastViT를 소개한다~
- 스킵 연결을 제거하기 위한 RepMixer 블록 사용
- 정확도를 향상시키기 위한 inear train-time overparameterization 사용
- Early stage에서 self-attention 레이어를 대체하기 위한 large convolutional kernels 사용
FastViT contribution
- 모바일 디바이스와 데스크톱 GPU 두 가지 플랫폼에서 가장 빠르다는 것을 보여줌
- Image classification, detection, segmentation, 3D mesh regression 테스크와 같은 다양한 작업에 일반화되는 것을 보여줌
- 모델이 오염 및 분포 밖 샘플에 강하며 경쟁 모델보다 훨씬 빠르다는 것을 보여줌
Architecture
Overview
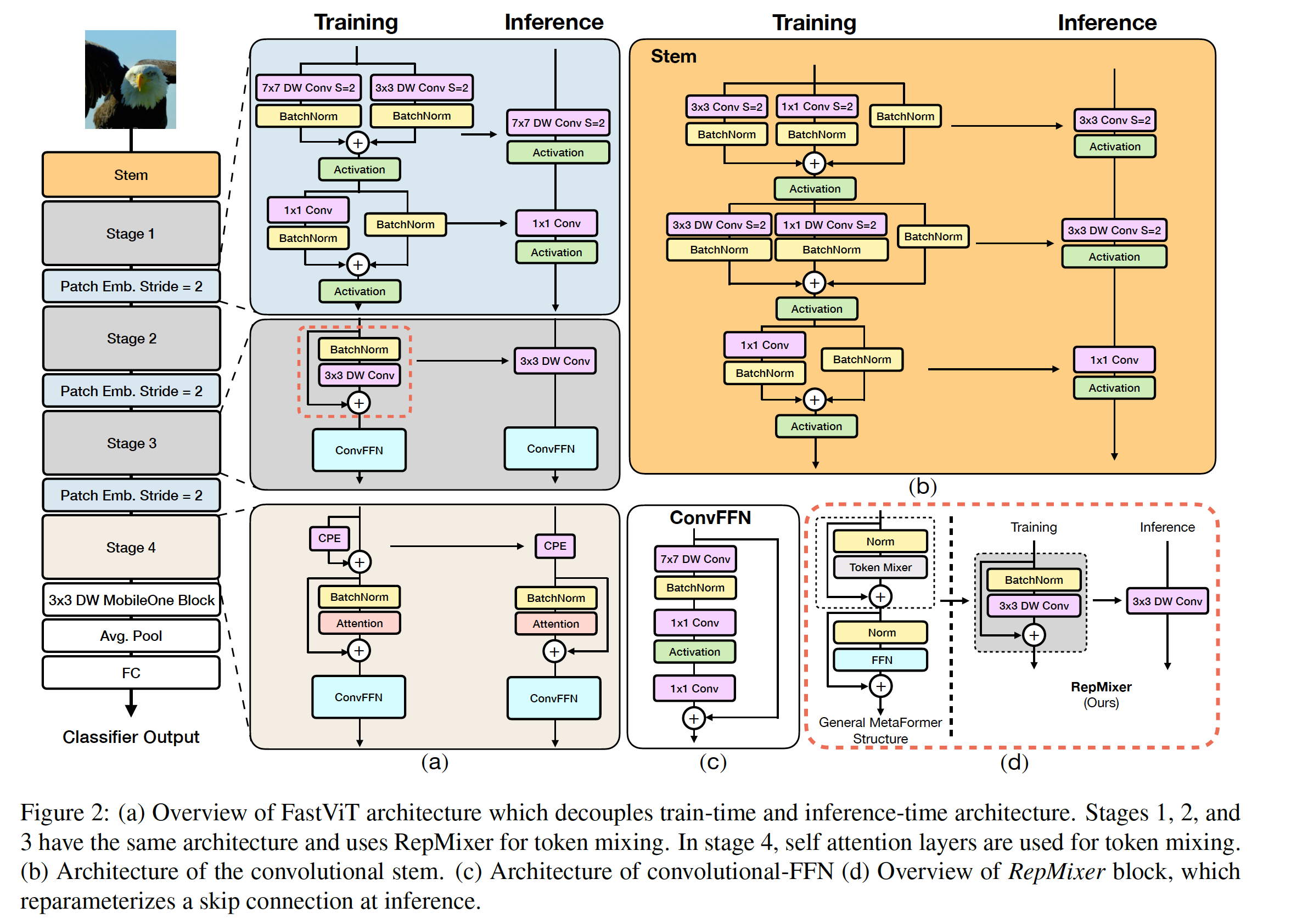
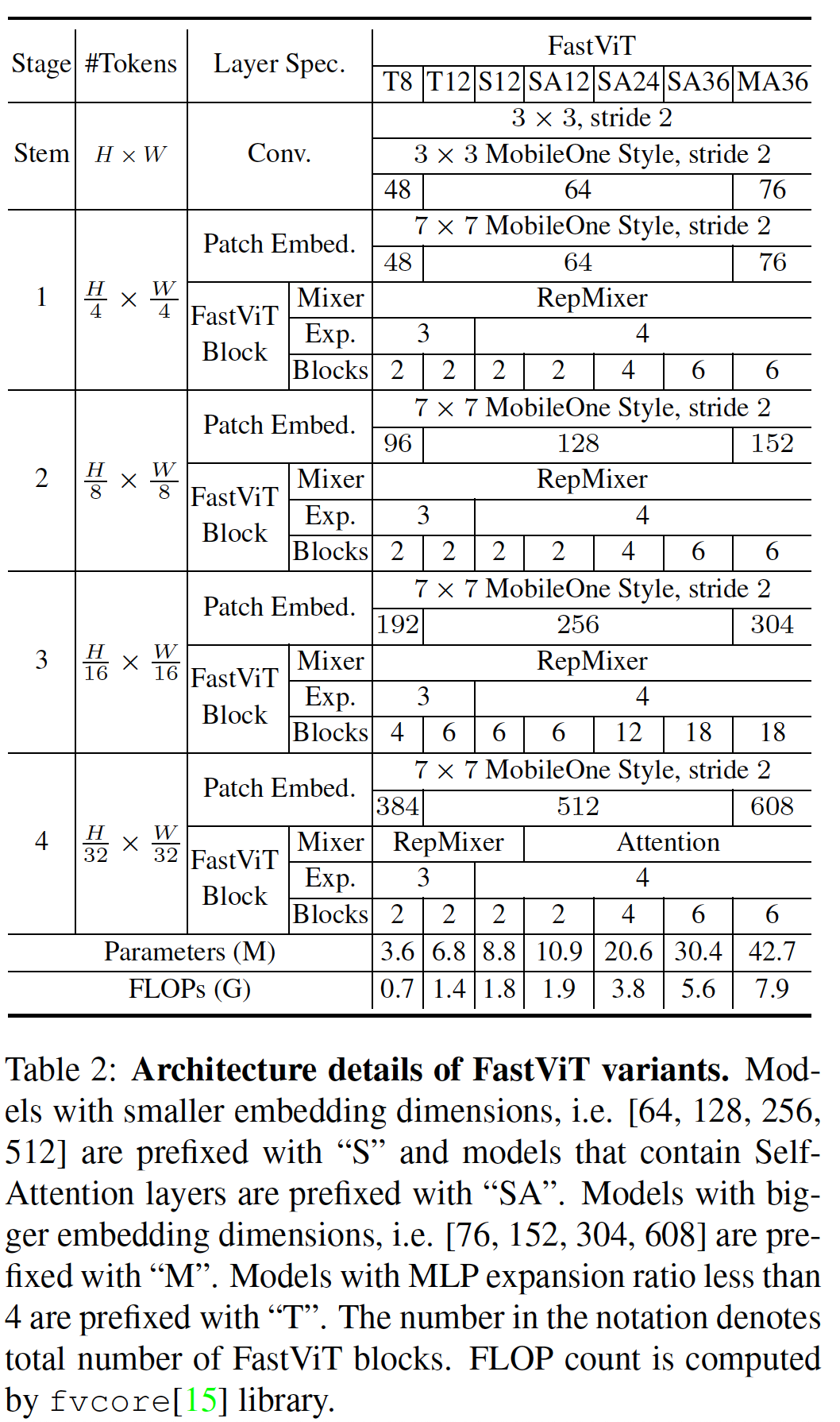
FastViT는 다양한 스케일에서 작동하는 네가지 독립적인 단계로 구성되어 있다 (Figure 2) 참조. Table 2는 FastViT variation을 보여줌.
FastViT은 RepMixer를 사용하는데, 이것은 skip connections을 reparameterize하여 메모리 액세스 비용을 낮추는데 도움이 되며(Figure 2d 참조),
효율성과 성능을 더 향상시키기 위해 일반적으로 stem 및 패치 임베딩 레이어에서 찾을 수 있는 밀집 k×k 컨볼루션을 train-time over parameterization를 사용한 팩터라이즈된(factorized) 버전으로 대체( Figure 2a 참조).
ViT의 self-attention token mixers는 특히 고해상도에서는 계산 비용이 많이 든다. 효율적인 버전의 self-attention 레이어가 연구되었지만, 네트워크 아키텍처 초기 단계에서 receptive fields를 향상시키는 효율적인 대안으로 large kernel convolution 을 사용(Figure 2c 참조).
FastViT
Reparameterizing Skip Connections
RepMixer
Convolutional mixing은 ConvMixer에서 소개되었다. 입력 텐서 X에 대한 믹싱 블록은 다음과 같이 구현된다.
σ : non-linear activation function
BN : Batch Normalization
DWConv : depthwise convolution layer
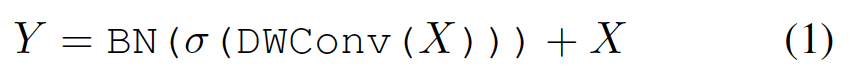
(1)에서 보여진 블록이 효과적인 것으로 ConvMixer에서 이야기되었지만, RepMixer에서는 간단히 재배치하고 σ를 제거한다.

이 설계의 가장 큰 장점은 추론 시점에 single depthwise convolutional 레이어로 reparametrized 할 수 있다는 것이다. (Figure 2d 참조)
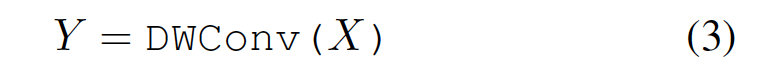
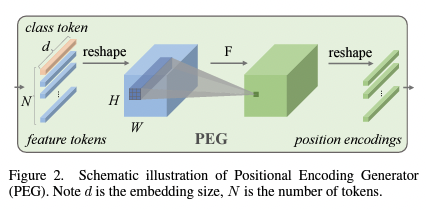
Positional Encodings
논문에선 입력 토큰의 로컬 이웃에 따라 동적으로 생성되고 조건이 부여되는 conditional positional encodings을 사용하며, 이러한 방법은 depth-wise conolution 연산자의 결과로 생성되며 패치 임베딩에 추가된다.
이 연산 그룹에는 비선형성이 없으므로 이 블록은 Figure 2a와 같이 reparameterize 된다.
Conditional Positional Encoding (CPE)
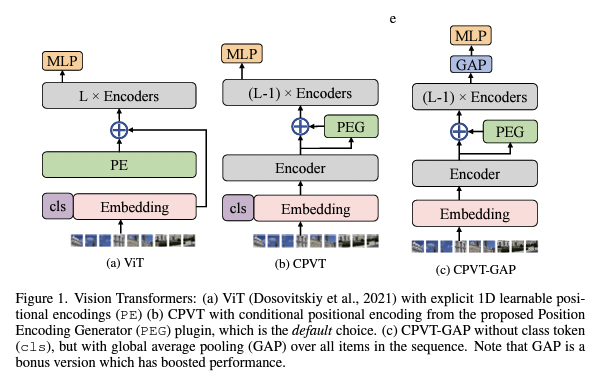
기존의 Positional Encoding은 주로 절대 위치 정보를 모델에 제공하기 위해 사용된다. 그러나 CPVT(CPE 제안한 논문)에서는 조건부 위치 인코딩을 도입하여 주변 이웃 정보를 고려한다.
이것은 이미지 내에서 주변 픽셀 또는 패치와의 관계를 고려하여 위치 정보를 조정합니다. 이로써 모델은 입력 이미지의 구조적 특징을 더 잘 파악할 수 있게 됩니다.
Note : d is the embedding size,N is the number of tokens.

# PEG from https://arxiv.org/abs/2102.10882
class PosCNN(nn.Module):
def __init__(self, in_chans, embed_dim=768, s=1):
super(PosCNN, self).__init__()
self.proj = nn.Sequential(nn.Conv2d(in_chans, embed_dim, 3, s, 1, bias=True, groups=embed_dim), )
self.s = s
def forward(self, x, H, W):
B, N, C = x.shape
feat_token = x
cnn_feat = feat_token.transpose(1, 2).view(B, C, H, W)
if self.s == 1:
x = self.proj(cnn_feat) + cnn_feat
else:
x = self.proj(cnn_feat)
x = x.flatten(2).transpose(1, 2)
return x
def no_weight_decay(self):
return ['proj.%d.weight' % i for i in range(4)]
Emperical Analysis
Skip connections reparameterizing의 이점을 확인하기 위해, latency 측면에서 가장 효율적인 토큰 믹서 중 하나인 Pooling 또는 RepMixer를 MetaFormer S12 아키텍처에서 비활성화(ablate)해서 실험. 모든 모델은 약 1.8G FLOPs이다.
iPhone 12 Pro에서 224 x 224 사이즈 이미지부터 1024 x 1024 사이즈 이미지까지 다양한 입력으로 모델에 넣고 시간을 잼.
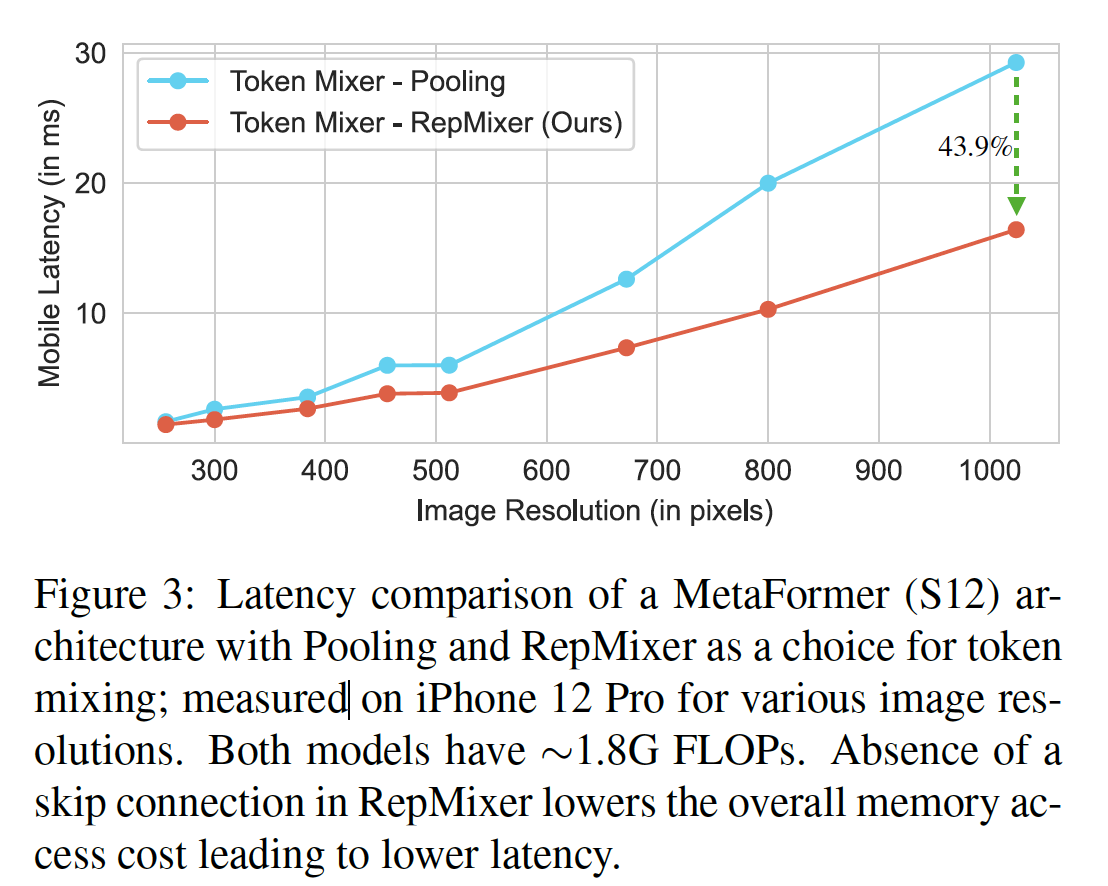
Figure3에서 보이듯 skip connections을 제거한 RepMixer가 훨씬 더 빠르다.
Linear Train-time Overparameterization
효율성(파라미터 수, FLOPs, latency)을 더욱 개선하기 위해 모든 dense k×k convolutions을 factorized 버전, 즉 k×k depthwise + 1×1 pointwise convolution 으로 대체한다.
그러나 factorization으로 인해 매개변수 수가 줄어들면 모델의 capacity가 감소할 수 있기 때문에, 인수분해된 레이어의 용량을 늘리기 위해 MobileOne에서 설명된 대로 linear train-time overparameterization을 한다.
MobileOne-style overparameterization은 stem, 패치 임베딩, projection layer에서 성능을 향상시키는 데 도움이 된다.
Table 3에서 train-time overparameterization이 FastViT-SA12 모델에서 ImageNet의 최상위 정확도를 0.6% 향상시키는 것을 보여준다. 더 작은 FastViT-S12 변형에서는 Table 1에서 Top-1 정확도가 0.9% 향상 되는 것을 보여준다.
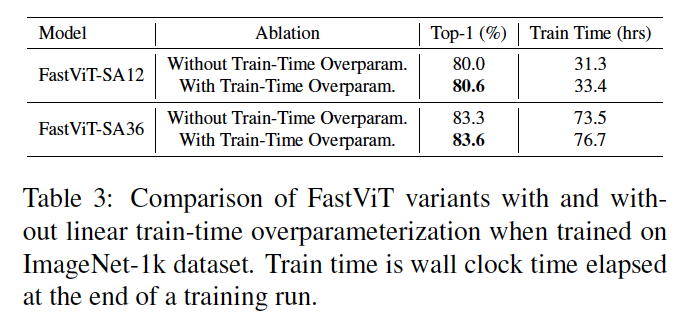
그러나 train-time overparameterization은 추가된 브랜치로 인한 계산 오버헤드로 인해 학습 시간이 증가한다는 점에 주목해야 한다. FastViT 아키텍처에서는 위에서 설명한 대로 밀집한 k×k 컨볼루션을 분해된 형태로 대체하는 레이어만 overparameterization을 적용한다 (이 레이어는 stem, 패치 임베딩, projection layer에서 찾을 수 있음).
이러한 레이어에서 발생하는 계산 비용은 네트워크의 나머지 부분보다 낮기 때문에 이러한 레이어를 overparameterization하더라도 학습 시간이 크게 증가하지 않는다. 예를 들어, train-time overparameterization을 사용하지 않고 Section 4.1에서 설명한 동일한 설정 하에서 해당 변형을 학습하는 것과 비교했을 때, FastViT-SA12는 학습 시간이 6.7% 더 걸리고, FastViT-SA36은 4.4% 더 오래 걸립니다.
Large Kernel Convolutions
RepMixer의 receptive field는 self-attention 토큰 믹서와 비교해서 지역적이다. 그러나 self-attention 기반의 토큰 믹서는 계산 비용이 많이 든다. Self-attention을 사용하지 않는 early stage의 receptive field를 향상시키기 위한 계산적으로 효율적인 방법은 depthwise large kernel convolutions을 통합하는 것이다.
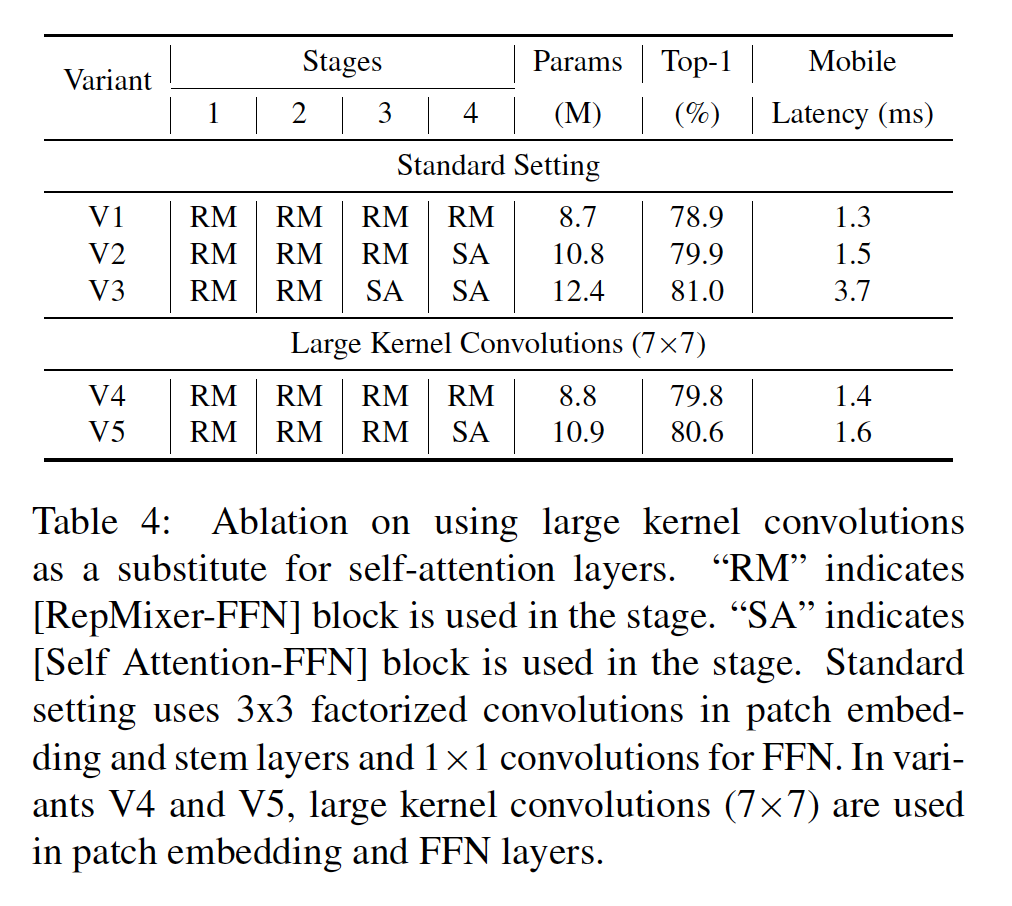
우리는 FFN 및 패치 임베딩 레이어에 depthwise largge kernel convolutions을 도입한다. Table 4에서 볼 때, depthwise largge kernel convolutions을 사용하는 변형은 상대적으로 작은 지연 시간 증가와 함께 self-attention 레이어를 사용하는 변형과 경쟁력 있는 성능을 제공할 수 있음을 알 수 있다.
V5와 V3을 비교할 때, 모델 크기는 11.2% 증가하고, Top-1 정확도가 0.4% 정도의 상대적으로 작은 이득을 얻으려면 지연 시간이 2.3배 증가. V2는 V4보다 20% 크며, ImageNet에서 유사한 Top-1 정확도를 달성하면서 V4보다 7.1% 더 높은 지연 시간을 갖는다.
Table 1에서 FFN 및 패치 임베딩 레이어의 depthwise largge kernel convolutions에 대한 실험을 보여준다. 전반적으로 depthwise largge kernel convolutions은 FastViT-S12의 Top-1 정확도를 0.9% 향상시켰다.
저자의 FFN (Feedforward Neural Network) 및 패치 임베딩 레이어의 아키텍처는 그림 2에 나와 있습니다. FastVit FFN 블록은 ConvNeXt 블록과 유사한 구조를 가지고 있지만 Layer Normalization 대신 Batch Normalization을 사용한다. 따라서 추론 시 이전 레이어와 병합(fuse)될 수 있으며, LayerNorm을 위한 적절한 텐서 레이아웃을 얻기 위한 추가적인 재구성 연산이 필요하지 않다.
또한, largge kernel convolutions은 수용 영역을 증가시키는 데 도움이 되며, 모델의 견고성을 향상시키는 데 도움이 된다. 그리고 convolution-FFN 블록은 일반적으로 "Towards robust vision transformer"에서 관찰된 바와 같이 vanilla-FFN 블록보다 견고할 가능성이 높다.
Experiments
Image Classification
학습 레시피는 아래와 같다.
- AdamW optimizer로 300 epochs을 학습, 0.05 weight decay
- Peak learning rate 10^-3
- Total Batch size 1024 (오와우..)
- 5 warmup epochs
- cosine schedule
- 8 NVIDIA A100
iPhone 레이턴시 측정을 위해 모델을 Core ML Tools (v6.0)을 사용하여 내보내고 iOS 16과 iPhone12 Pro Max에서 실행하며 모든 모델에 대해 배치 크기를 1로 설정
GPU 레이턴시 측정을 위해 추적된 모델을 TensorRT (v8.0.1.6) 형식으로 내보내고 배치 크기를 8로 설정하여 NVIDIA RTX-2080Ti에서 100회 실행한 결과 중 중앙값 레이턴시 추정치를 계산
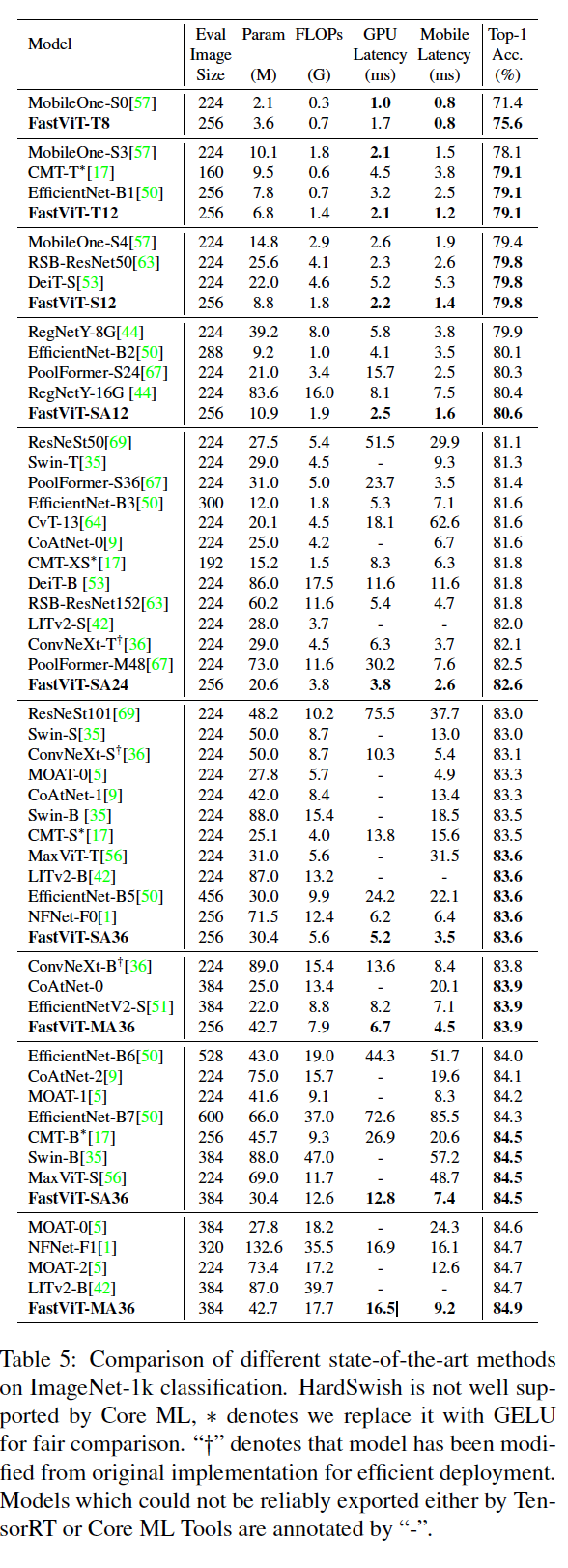
→ Top-1 정확도가 83.9%인 경우, FastViT-MA36은 iPhone 12 Pro에서 최적화된 ConvNeXt-B 모델보다 1.9배 빠르며, GPU에서는 2.0배 빠르다.
Top-1 정확도가 84.9%인 경우, FastViT-MA36은 GPU에서 NFNet-F1 [1]과 동일한 속도를 제공하면서 크기는 66.7% 더 작고 FLOPs는 50.1% 적게 사용하며, 모바일 기기에서는 42.8% 더 빠르다.
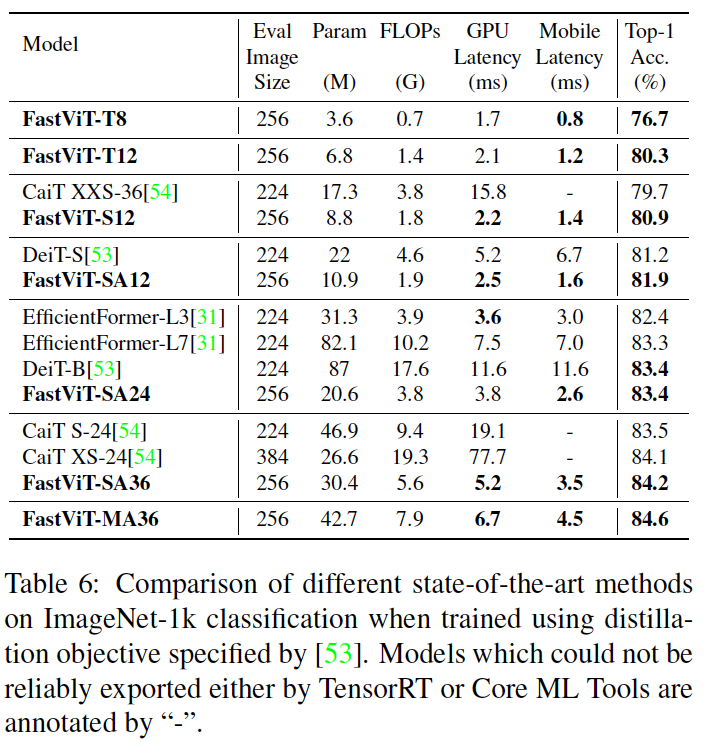
→ FastViT-SA24는 EfficientFormer-L7과 유사한 성능을 달성하면서 매개변수가 3.8배 더 적고, FLOPs가 2.7배 더 적으며, 레이턴시가 2.7배 더 낮은 결과를 보인다.
Robustness Evaluation
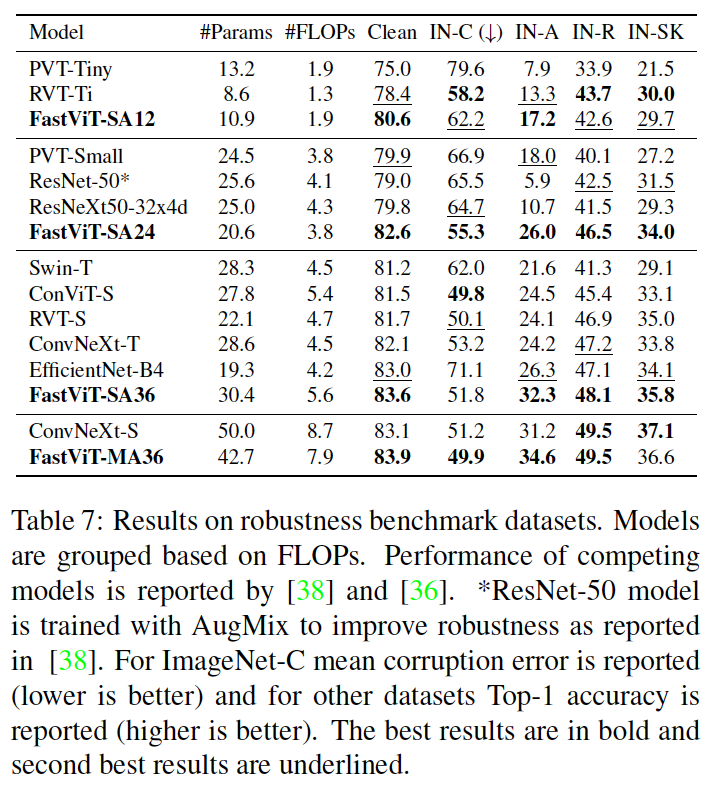
다음과 같은 벤치마크에서 모델의 이상 분포 견고성을 평가
(i) ImageNet-A [24], ResNets에 의해 오분류되는 자연 발생 예제를 포함하는 데이터셋
(ii) ImageNet-R [22], 다른 질감과 지역 이미지 통계를 가진 ImageNet 객체 클래스의 자연적 렌더링을 포함하는 데이터셋
(iii) ImageNet-Sketch [58], google 이미지 쿼리를 사용하여 얻은 모든 ImageNet 클래스의 흑백 스케치를 포함하는 데이터셋
(iv) ImageNet-C [23], ImageNet 테스트 세트에 적용된 알고리즘적으로 생성된 손상 (흐림, 노이즈)을 포함하는 데이터셋
→ Table 7에서 FastViT는 RVT와 ConvNeXt에 대해 경쟁력 있고, 사실 FastViT-M36은 더 많은 매개변수를 가지고 있으면서 저자가 제안한 모델보다 10% 더 FLOP을 사용하는 ConvNeXt-S보다 깨끗한 정확성, 손상에 대한 견고성 및 이상 분포 견고성이 유사하다는 것을 보여준다.
3D Hand mesh estimation
최근의 real-time 3D hand mesh estimation 연구는 주로 CNN 기반 백본 네트워크에 complex mesh regression layer를 사용한다. 대부분의 하드웨어 장치가 2D CNN에서 특징 추출에 매우 최적화되어 있는 반면, 이러한 방법에서 사용되는 복잡한 complex mesh regression head에서는 그렇지 않다. 여기서는 complex mesh regression head를 mple regression module로 대체한다.
저자들은 이미지의 기본적인 표현을 잘 학습하는 특징 추출 백본을 사용하면 메시 회귀의 학습 어려움을 완화할 수 있다고 생각하기 때문에, 다른 실시간 방법은 특징 추출 백본의 부족함을 복잡한 complex mesh regression layer로 보완하는 반면, 저자들은 더 좋은 특징 추출 백본을 사용하고 간단한 mesh regression layer를 사용한다.
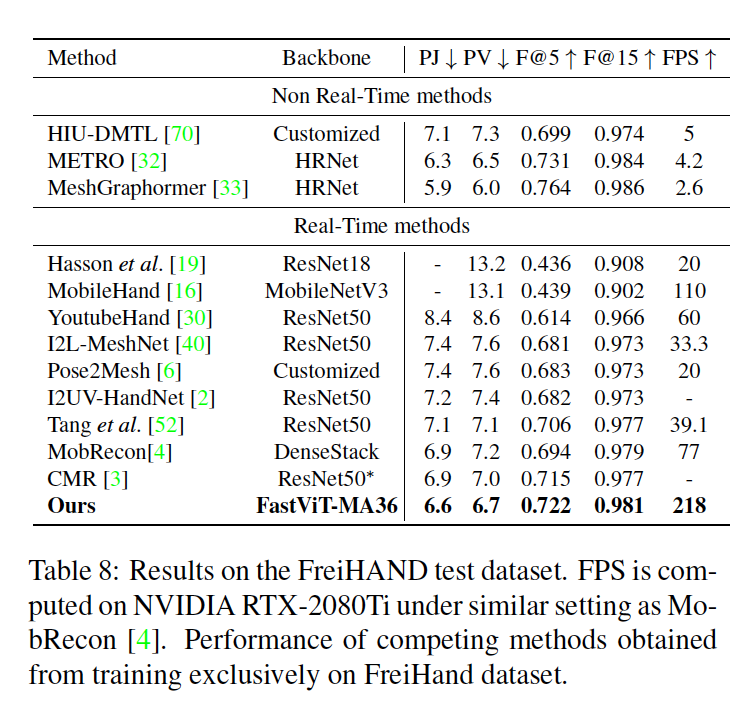
→ Table 8을 보면 real-time 방법 중에서 FastViT가 모든 관절 및 정점 오차 관련 지표에서 다른 방법을 능가하며 MobileHand보다 1.9배 빠르고 최신 기술인 MobRecon보다 2.8배 빠르다는 것을 보여준다
Semantic Segmentation and Object Detection
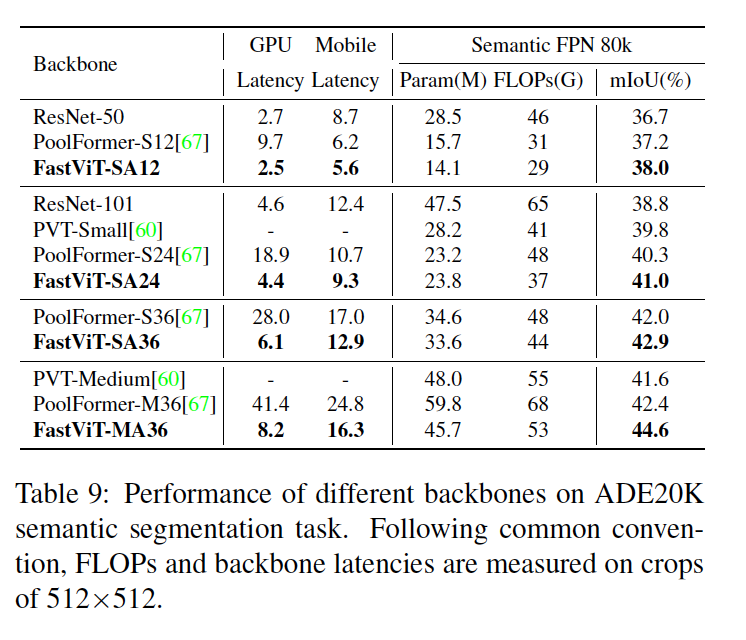
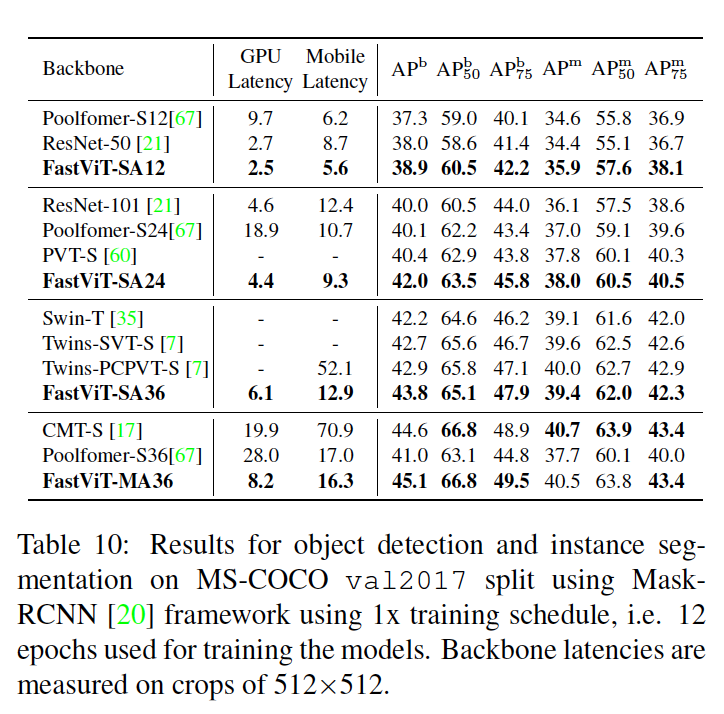
Semantic FPN 디코더를 사용하여 시맨틱 세그멘테이션 모델을 훈련한다(모든 모델은 해당 이미지 분류 모델의 사전 훈련된 가중치로 초기화한다).
높은 해상도의 입력 이미지로 인해 Table 9 및 Table 10 모두에서 GPU 레이턴시는 배치 크기 2에서 추정.
Table 9
- ADE20k 데이터셋으로 검증한다. 이 데이터셋은 150가지 시멘틱 카테고리를 포함한 20,000개의 훈련 이미지와 2,000개의 검증 이미지를 가지고 있음
- Recent work와 FastViT를 비교
- FastViT-MA36 모델은 데스크톱 GPU와 모바일 장치에서 모두 더 높은 FLOP, 파라미터 수 및 레이턴시를 가진 PoolFormer-M36보다 5.2% 더 높은 mIoU를 달성
Table 10
- MS-COCO 데이터셋에서 80개 클래스를 포함한 118,000개의 훈련 이미지와 5,000개의 검증 이미지로 object detection model 학습
- Recent work와 FastViT를 비교.
- 모든 모델은 Mask-RCNN 헤드를 사용하여 Metaformer을 따라 1x schedule으로 훈련됩니다.
- FastViT-MA36 모델은 CMT-S와 유사한 성능을 달성하면서 데스크톱 GPU 및 모바일 장치에서 각각 2.4배와 4.3배 더 빠름.
Conclusion
모바일 장치와 데스크톱 급 GPU와 같은 다양한 컴퓨팅 환경에서 효율적인 일반용 하이브리드 비전 트랜스포머를 제안함. Structural reparameterization을 통해 모델이 메모리 액세스 비용을 줄이게 되고, 이로 인해 높은 해상도에서 특히 실행 시간에서 큰 개선이 이루어졌다.
또한, 이미지넷 분류 작업 및 객체 감지, 시맨틱 세그멘테이션 및 3D 핸드 메쉬 추정과 같은 downstream task에서 성능을 향상시키기 위한 추가 아키텍처 변경을 제안. 실험적으로 FastViT 백본이 분포 밖 샘플에 대해 매우 강력하며 경쟁 모델보다 훨씬 빠르다는 것을 보였다.
'DL|ML' 카테고리의 다른 글
| Lecture 01 - Introduction to Computer Vision and Visual Odometry : Understanding Check (2) | 2024.01.02 |
|---|---|
| Vision Algorithms for Mobile Robotics (1) | 2024.01.02 |
| Google I/O 2023과 Keras Core (0) | 2023.07.15 |
| multi gpu 사용 가능 환경에서 cpu 사용하기 (0) | 2023.06.10 |
| [Tübingen ML] Computer Vision - Lecture 3.4 (Structure-from-Motion: Bundle Adjustment) (2) | 2023.04.25 |

