원문 출처
https://ai.googleblog.com/2021/07/mapping-africas-buildings-with.html
Mapping Africa’s Buildings with Satellite Imagery
Wednesday, July 28, 2021
Posted by John Quinn, Software Engineer, Google Research, Ghana
건물의 면적(Building footprints)에 대한 정확한 기록은 인구 추정 및 도시 계획에서 인도적 대응 및 환경 과학에 이르기까지 다양한 응용 분야에서 중요합니다. 홍수나 지진과 같은 재해가 발생한 후 당국은 얼마나 많은 가구가 영향을 받았는지 추정해야 합니다. 이상적으로는 이에 대한 최신 인구 조사 정보가 있지만 실제로는 그러한 기록이 오래되었거나 사용하지 못할 수도 있습니다. 대신 건물의 위치와 건물의 밀도에 대한 데이터는 유용한 대체 정보 소스가 될 수 있습니다.
이러한 데이터를 수집하는 좋은 방법은 위성 이미지를 사용하여 특히 고립되어 있거나 접근하기 어려운 지역에서 전 세계 건물 분포를 매핑할 수 있습니다. 그러나 일부 환경에서 컴퓨터 비전 방식으로 건물을 탐지하는 것은 어려운 작업이 될 수 있습니다. 위성 영상은 지상에서 수백 킬로미터 떨어진 곳에서 촬영해야 하기 때문에 고해상도(픽셀당 30~50cm)에서도 작은 건물이나 텐트 쉼터는 몇 픽셀만 차지합니다. 비공식 거주지나 자연에서 나온 소재로 지어진 건물이 주변 환경과 시각적으로 조화를 이룰 수 있는 시골 지역에서는 작업이 훨씬 더 어렵습니다. 또한 위성 이미지(overhead imagery)에서 건물과 쉽게 혼동될 수 있는 많은 유형의 자연적 및 인공적 특징들이 있습니다.

"Continental-Scale Building Detection from High-Resolution Satellite Imagery"에서 우리는 사바나, 사막, 숲과 같은 다양한 지형에 걸쳐 시골 및 도시 환경에서 비공식 정작치와 난민 시설을 탐지하는 새로운 방법을 사용하여 이러한 과제를 해결합니다. 우리는 이 건물 탐지 모델을 사용하여 아프리카 대륙 대부분에 걸쳐 있는 5억 1,600만 건물의 위치와 면적을 포함하는 새로운 개방형 액세스 데이터 리소스인 Open Buildings 데이터셋을 만듭니다 . 데이터셋은 재난 대응 또는 인구 매핑에서 새로운 의료 시설과 같은 서비스 계획 또는 자연 환경에 대한 인간의 영향 연구에 이르기까지 여러 실용적, 과학적, 인도적 응용 프로그램을 지원할 것입니다.
모델 개발
100k 이미지에서 175만 개의 건물에 수동으로 레이블을 지정하여 건물 탐지 모델에 대한 학습 데이터 셋을 구축했습니다. 아래 그림은 우리가 아프리카 대륙 전역에 걸쳐 여러 지역의 혼란스러운 특성을 고려하여 학습 데이터의 이미지에 레이블을 지정하는 방법의 몇 가지 예를 보여줍니다. 예를 들어, 시골 지역에서는 다양한 유형의 주거지를 식별하고 자연적 특징과 구분해야 했으며 도시 지역에서는 밀집되고 인접한 구조물에 대한 라벨링 정책을 개발해야 했습니다.

먼저 각 픽셀을 건물 또는 건물이 아닌 것으로 분류한 다음, 이러한 픽셀을 개별 인스턴스로 그룹화하여 바텀-업 방식으로 건물을 탐지하도록 모델을 학습했습니다. 탐지 파이프라인은 위성 이미지 분석에 일반적으로 사용되는 U-Net 모델을 기반으로 했습니다. U-Net의 장점 중 하나는 아키텍처가 비교적 컴팩트하기 때문에 많은 양의 이미징 데이터에 큰 컴퓨팅 부담 없이 적용할 수 있다는 것입니다. 대륙 규모의 위성 이미지에 이것을 적용하는 최종 작업은 수십억 개의 이미지 타일에서 모델을 실행하는 것을 의미하기 때문에 이 사실은 중요합니다.

기본 모델을 사용한 초기 실험은 정밀도와 재현율이 낮았습니다. 예를 들어 건물과 같은 외관을 가진 다양한 자연적 및 인공적 특징들이 있었기 때문입니다. 우리는 성능을 향상시키는 여러 방법을 찾았습니다. 하나는 정규화 방법인 믹스업(mixup) 을 사용하는 것이었습니다. 무작위 훈련 이미지에 가중 평균(weighted average)을 함께 혼합하는 것 입니다. 원래는 이미지 분류를 위해 믹스업을 제안했지만, 시멘틱 세그먼테이션(semantic segmentation)에 사용하도록 수정했습니다. 100,000개의 학습 이미지가 있더라도 학습 데이터는 테스트 시간에 모델이 제시하는 지형, 대기 및 조명 조건의 전체 변화를 포착하지 못하기 때문에 이 건물 세그먼테이션 작업에는 일반적으로 정규화가 중요합니다. 이런 이유 때문에 오버피팅의 경향을 보입니다. 이것은 훈련 이미지의 무작위 증가뿐만 아니라 혼합에 의해서도 완화될 수 있습니다.
우리가 효과적인 것으로 판명한 또 다른 방법은 셀프 트레이닝(self-training)을 사용하는 것입니다. 우리는 아프리카 전역에서 1억 개의 위성 이미지 셋을 준비하고, 대부분 건물이 포함된 870만 개의 이미지 하위 집합으로 필터링했습니다. 이 데이터 셋은 Noisy Student 방법을 사용한 self-training에 사용 되었으며, 이전 단계의 최고의 건물 탐지 모델의 출력을 '선생님'으로 사용하여 증강된 이미지(augmented images)에서 유사한 예측을 하는 '학생' 모델을 학습시키는 방법입니다. 실제로, 우리는 이것이 오탐을 줄이고 탐지 출력을 날카롭게 한다는 것을 발견했습니다. 학생 모델은 건물에 더 높은 컨피던스 값을 부여하고 배경에 더 낮은 컨피던스 값을 부여했습니다.

우리가 처음에 직면한 한 가지 문제는, 우리 모델이 명확하게 묘사된 가장자리가 없고 이웃 건물이 함께 병합되는 "뚜렷하지 않은(blobby)" 탐지를 하는 경향이 있다는 것입니다. 이를 해결하기 위해 원본 U-Net 논문 의 다른 아이디어를 적용했습니다. 이는 거리 가중치(distance weighting)를 사용하여 손실 함수를 조정해서 경계 근처에서 정확한 예측을 하는 것의 중요성을 강조하는 것입니다. 학습 중에 거리 가중치는 손실에 가중치를 추가하여 가장자리에 더 큰 강조점을 둡니다 - 특히 거의 닿는 인스턴스들이 있는 경우에 그렇습니다. 건물 탐지의 경우 이는 모델이 건물 사이의 간격을 올바르게 식별하도록 도와주며, 많은 가까운 구조가 함께 병합되지 않도록 하는 것이 중요합니다. 우리는 원래의 U-Net 거리 가중치 공식이 도움이 되지만 계산이 느리다는 것을 발견했습니다. 그래서 우리는 더 빠르고 효과적인 가장자리의 가우시안 컨볼루션(Gaussian convolution)을 기반으로 한 대안을 개발했습니다.

우리의 테크니컬 레포트에 이 방법에 대한 더 많은 설명이 포함되어 있습니다.
결과
우리는 도시, 시골 및 중간 밀도와 같은 다양한 카테고리의 대륙의 여러 지역에서 모델의 성능을 평가했습니다. 또한 잠재적인 인도적 지원에 대비하기 위해 실향민과 난민 정착지가 있는 지역에서 모델을 테스트했습니다. 정밀도와 재현율은 지역마다 다르기 때문에 대륙 전체에서 일관된 성능을 달성하는 것은 지속적인 과제입니다.

낮은 스코어 영역에 대한 탐지를 시각적으로 검사할 때 다양한 원인을 확인했습니다. 농촌 지역에서는 라벨링 오류가 문제였습니다. 예를 들어, 대부분 비어 있는 지역 내의 단일 건물은 라벨러가 식별하기 어려울 수 있습니다. 도시 지역에서 모델은 큰 건물을 별도의 인스턴스로 나누는 경향이 있습니다. 이 모델은 배경과 건물을 구분하기 어려운 사막 지형에서도 성능이 떨어졌습니다.
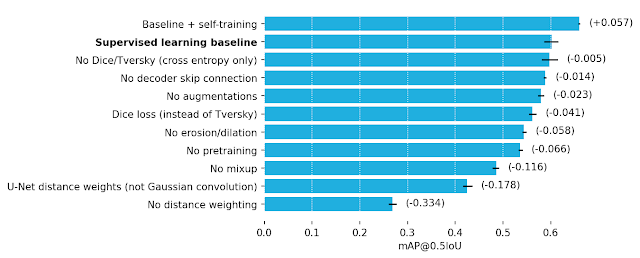
Mean average precision(mAP)으로 측정한 최종 성능에 가장 크게 기여한 방법을 이해하기 위해 ablation study를 수행했습니다. 거리 가중치, 믹스업 및 ImageNet 사전 학습의 사용은 지도 학습(supervised learning) 기준의 성능에 가장 큰 요인이었습니다. 이러한 방법을 사용하지 않은 절제된 모델은 각각 -0.33, -0.12 및 -0.07의 mAP 차이를 가졌습니다. 비지도 학습(unsupervised learning)은 +0.06 mAP의 상당히 향상된 모습을 보였습니다.
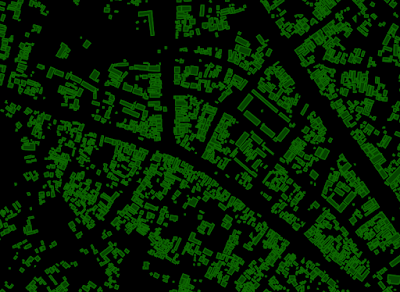
Open Buildings 데이터셋 만들기
최종 데이터셋을 만들기 위해, 아프리카 대륙의 위성 이미지(대륙의 64%인 1,940만 km²를 차지하는 86억 개의 이미지 타일)에 최고의 건물 탐지 모델을 적용했고, 그 결과 516M의 구별된 구조를 탐지했습니다.
각 건물의 윤곽은 폴리곤으로 단순화되었으며 플러스 코드(Plus Code)와 연관되었습니다. 플러스 코드는 도로 주소와 유사한 숫자와 문자로 구성된 식별자로, 공식적인 주소 지정 시스템이 없는 지역의 건물을 식별하는 데 유용합니다. 또한 특정 정밀도 수준을 달성하기 위해 제안된 스레시홀드 대한 컨피던스 스코어와 가이드를 포함합니다.
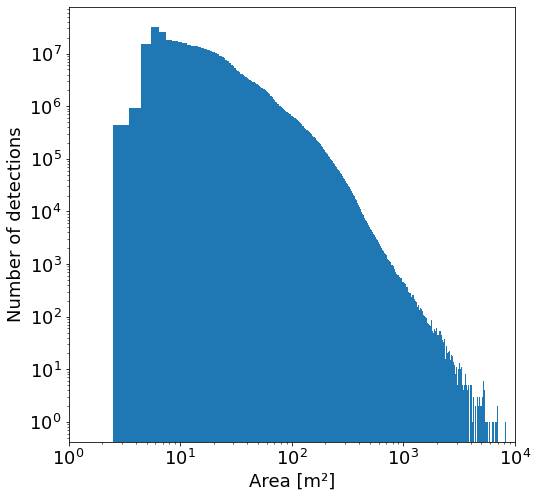
구조물의 크기는 아래와 같이 다양하며, 작은 면적인 경향이 있습니다. 예를 들어, 비공식 거주지나 난민 시설에 대한 분석을 지원하려면 작은 구조를 포함하는 것이 중요합니다.
이 데이터는 자유롭게 이용할 수 있고 우리는 그것이 어떻게 사용되는지 듣기를 기대합니다. 향후 사용처와 피드백에 따라 새로운 기능과 지역을 추가할 수 있습니다.
감사의 말
이 작업은 AI for Social Good 노력의 일부이며 가나의 Google Research에서 주도했습니다. 이 작업의 공동 저자: Wojciech Sirko, Sergii Kashubin, Marvin Ritter, Abigail Annkah, Yasser Salah Eddine Bouchareb, Yann Dauphin, Daniel Keysers, Maxim Neumann 및 Moustapha Cisse. 조정에 도움을 준 Abdoulaye Diack, Sean Askay, Ruth Alcantara 및 Francisco Moneo에게 감사드립니다. Rob Litzke, Brian Shucker, Yan Mayster 및 Michelina Palone은 지리 기반 시설에 대한 귀중한 지원을 제공했습니다.
번역자의 말
이 글을 읽기 위하여 필요한 배경지식
- Segmentation
- Supervised Learning
- Unsupervised Learning
- U-Net
- Gaussian Convolution
- Self training
- mAP
'DL|ML' 카테고리의 다른 글
| model.fit()에서 벗어나기! (2) (0) | 2022.04.20 |
|---|---|
| model.fit()에서 벗어나기! (1) (0) | 2022.02.07 |
| <혼자 또는 같이하는 머신러닝 스터디 잼> 티셔츠 대장정의 끝 (0) | 2021.05.20 |
| 정확히 CNN에서 shared weights란 무엇을 의미하나요? (0) | 2021.05.12 |
| [논문리뷰] 모델을 가볍게 MobileNetV1, Depthwise Separable Convolution 설명 (2) | 2021.04.26 |



