논문, 코드

Self Supervised Learning를 여행하는 히치하이커를 위한 안내서
저는 요즘 모두의 연구소에서 Self Supervised Learning(SSL)을 공부하고 SSL에 대해 논문을 쓰는 것을 목표로 하는 SSL LAB(쓸랩)의 연구원으로도 활동하고 있습니다. 이번 논문은 infoNCE loss를 기반으로 predictive model을 사용하는 모델을 제안했습니다. infoNCE loss는 contrastive learning 논문에 자주 등장합니다. 잘 알고 가면 좋을 것 같습니다.
미리 알아두면 좋은 지식
- Contrastive Learning
: Positive pair와 Negative pair로 구성하여 Positive pair 끼리는 거리를 좁히고, Negative pair끼리는 거리를 멀리 띄워놓는 것
- infoNCE
: Contrastive Learning에 사용되는 Loss 중 하나
- Predictive Model
: 미래(다음에 나올 단어, 내일 날씨, 다음에 나올 픽셀 등이 될 수 있음) 를 예측하는 모델
Representation Learning with Contrastive Predictive Coding
이 모델은 배경지식이 꽤 필요합니다. 모델이 제안하는 것들에 대한 지식을 함께 따라가면서 논문 전체를 알아가려고 합니다.
모델이 제안하는 것
1) 조건부 예측이 모델링하기 더 쉽고 훨씬 더 컴팩트한 latent embedding space로 고차원 데이터를 압축합니다.
➔ representation을 잘하는 모델을 만들 것.
2) Latent space에서 강력한 autoregressive 모델을 사용하여 미래의 많은 steps을 예측합니다.
➔ 제안하는 모델은 예측 모델이다.
3) 자연어 모델에서 word embedding을 학습하는 데 사용되었던 유사한 방식으로 손실 함수에 대해 Noise-Contrastive Estimation
에 의존하여 전체 모델이 학습될 수 있도록 합니다.
➔ 여기서 말하는 word embedding 자연어 모델은 word2Vec 입니다. Word2Vec은 contrastive loss를 사용하여 이웃한 단어를 예측하였고, 제안하는 모델이 constrastive loss인 infoNCE를 사용할 것이라는 의미입니다.
요약하면 contrastive loss를 사용하여 representation을 잘 학습하는 예측 모델을 만들 것이라고 생각하면 되겠습니다.
Unsupervised Learning을 선택한 이유
Supervised Learning 모델이 sota를 달성하고 있고 많은 real-world applications에서 사용되고 있습니다. Supervised Learning 모델은 하나의 supervised task를 해결하는데에 specialized 되어있습니다. 예를 들어, 이미지 분류를 위해 추출된 feature는 image classification도메인의 정보를 가지고 있지만 image captioning에 필요한 색, 숫자 세는 능력(ability to count)과 같은 정보들은 제대로 가지고 있지 않습니다. 따라서 여러 task에 사용하기 위해서는 less specialized 하여야하고, Unsupervised Learning을 사용하여 데이터의 representation을 잘 표현하도록 학습하는 것이 좋습니다.
Unsupervised Learning의 가장 흔한 전략은 미래, 누락, 컨텍스트를 예측하는 것입니다. 이런 아이디어는 predictive coding의 오래된 방법 중 하나입니다.
미리보는 아키텍처
살짝 아키텍처를 봅시다. 전체적인 흐름은 다음과 같습니다. 데이터를 잘라서 인코더 $g_{enc}$에 넣어주고 얻은 $z_t$를 autoregressive model $g_{ar}$에 넣어 $c_t$를 얻습니다. 아직은 모르겠지만 현재 시점과 이전 시점의 데이터 $x$들로 구한 $c_t$와 미래 시점의 $z_{t+n}$ (n≥1)를 이용하여 학습하는 것 같습니다. 어떻게 되는건지 아래에서 더 자세하게 보겠습니다.
Representation을 어떻게 잘 학습하려고 하는걸까?
High-dimensional data 예측에 필요한 모델은 계산 집약적이며 종종 컨텍스트 c를 무시하고 데이터 x의 복잡한 관계를 모델링하는 데 용량을 낭비합니다. 이러한 문제를 해결하기 위해 논문이 제안한 모델의 주요 직관은 high-dimensional 신호의 다른 부분 간에 기본 공유 정보(shared information)를 인코딩하는 representation을 배우는 것입니다. 미래 정보를 예측할 때, 정의된 original signal x와 c의 mutual information를 최대한 보존하는 방식으로 x(미래)와 컨텍스트 c(현재)를 compact distributed vector representations을 학습합니다.
위의 mutual information 식을 보면 mutual information $I(x;c)$는 density ratio인 $\frac{p(x|c)}{p(x)}$에 비례합니다. (왜 $p(x, c)$는 무시되는 걸까요? 아시는 분은 댓글 부탁드립니다 🥺)
그렇다면 어떻게 Mutual Information을 최대한 보존할까?
mutual information이 density ratio에 비례하기 때문에 $x_{t+k}$와 $c_t$사이의 mutual information을 보존하는 density ratio $f$를 모델링합니다.
$f$는 다양한 양(positive)의 실수를 표현하는 식을 사용할 수 있지만 논문에서는 log-bilinear model을 사용합니다. $W_{k}^{T} c_{t}$는 매 스텝 $k$ 마다의 $w_k$를 의미합니다.
위의 Architcture를 되새기며 정리한다면 다음과 같을 것입니다.
- $g_{enc}$ : ResNet blocks
- $g_{ar}$ : GRU (최근에는 더 나은 결과를 낸 masked convolutional architectures 또는 self-attention networks를 사용한 결과도 있음)
- $c_{t} = g_{ar} (z≤t)$
- $z_{t}$와 $c_{t}$가 downstream task에서 사용할 수 있는 representation
InfoNCE Loss 그리고 Mutual Information Estimation
전체적인 모델은 mutual information을 최대화 해야하고 그렇다면 그에 비례하는 density ratio $f_k(x_{t+k}, c_t)$를 최대화하는 방향으로 가게됩니다. 그것을 위해 아래의 infoNCE loss를 쓰게 됩니다.
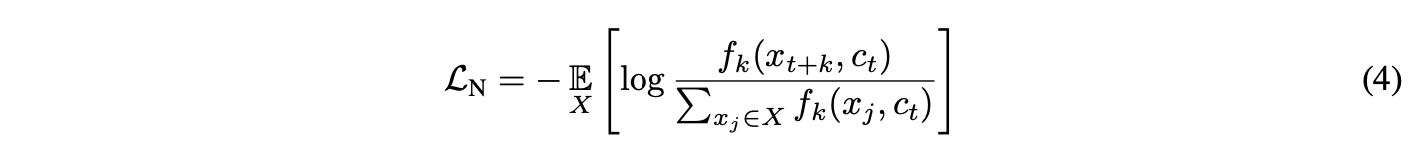
위의 Loss가 작아지기 위해선 $f_k(x_{t+k}, c_t)$가 커져야 합니다. 그렇게되면 이전에 말한 개념인 $x$와 $c$의 mutual information이 최대가 되는 것과 같은 의미입니다.
여러 분야에 적용한 실험 결과
Audio
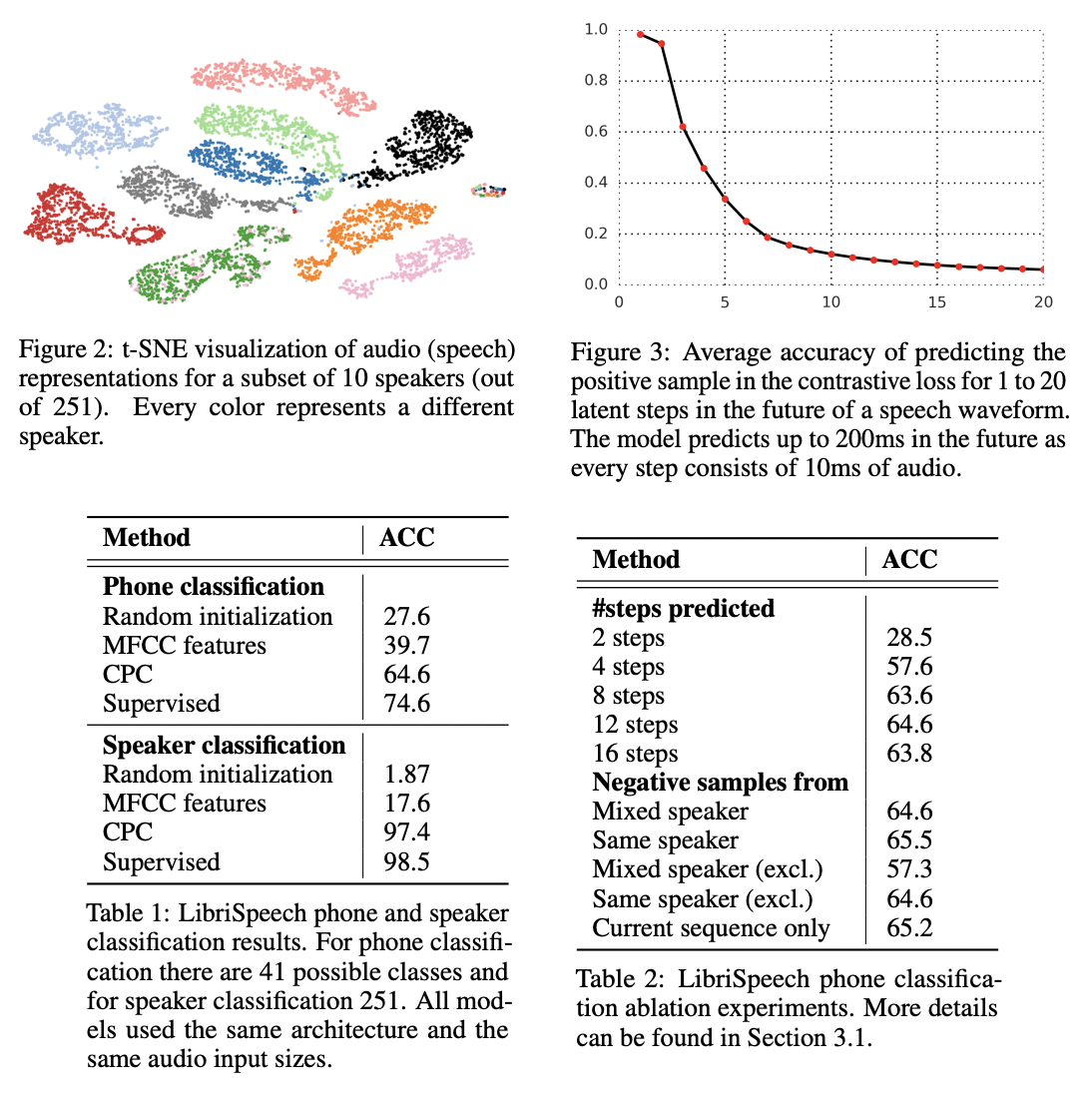
아래에서 보이는 Figure2는 화자(speaker) 분류의 결과입니다. 시각화 결과를 봤을 때 아주 잘되고 있는 것을 확인할 수 있고 아래의 Table 1, 2에서 CPC가 supervised에 준하는 성능을 내고 있다는 것을 알 수 있습니다.
Vision
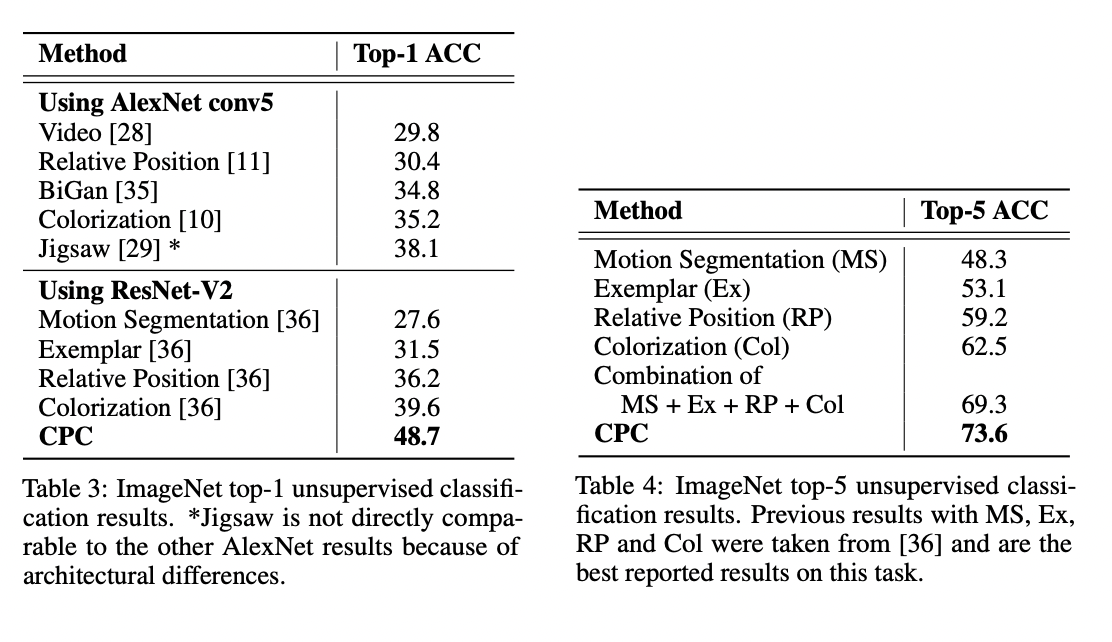
Vision 분야에서는 Table 3, 4를 참고해서 CPC가 sota를 달성했다는 것을 알 수 있습니다.
NLP
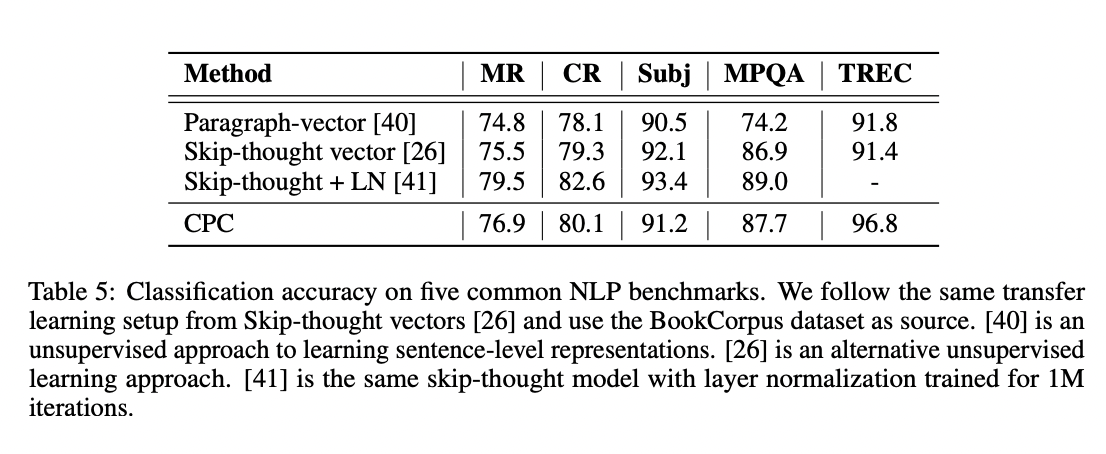
NLP에서도 좋은 성능을 내고 있다는 사실을 알 수 있습니다.
Representation Learning withContrastive Predictive Coding Code
CPC에서 코드를 중요하게 볼 부분은 아무래도 encoder, auto regressive, negative 후보를 정하는 부분, loss 함수 정도가 될 것 같습니다. 한 번 확인해봅시다.
| class CDCK2(nn.Module): | |
| def __init__(self, timestep, batch_size, seq_len): | |
| super(CDCK2, self).__init__() | |
| self.batch_size = batch_size | |
| self.seq_len = seq_len | |
| self.timestep = timestep | |
| self.encoder = nn.Sequential( # downsampling factor = 160 | |
| nn.Conv1d(1, 512, kernel_size=10, stride=5, padding=3, bias=False), | |
| nn.BatchNorm1d(512), | |
| nn.ReLU(inplace=True), | |
| nn.Conv1d(512, 512, kernel_size=8, stride=4, padding=2, bias=False), | |
| nn.BatchNorm1d(512), | |
| nn.ReLU(inplace=True), | |
| nn.Conv1d(512, 512, kernel_size=4, stride=2, padding=1, bias=False), | |
| nn.BatchNorm1d(512), | |
| nn.ReLU(inplace=True), | |
| nn.Conv1d(512, 512, kernel_size=4, stride=2, padding=1, bias=False), | |
| nn.BatchNorm1d(512), | |
| nn.ReLU(inplace=True), | |
| nn.Conv1d(512, 512, kernel_size=4, stride=2, padding=1, bias=False), | |
| nn.BatchNorm1d(512), | |
| nn.ReLU(inplace=True) | |
| ) | |
| self.gru = nn.GRU(512, 256, num_layers=1, bidirectional=False, batch_first=True) | |
| self.Wk = nn.ModuleList([nn.Linear(256, 512) for i in range(timestep)]) | |
| self.softmax = nn.Softmax() | |
| self.lsoftmax = nn.LogSoftmax() | |
| def _weights_init(m): | |
| if isinstance(m, nn.Linear): | |
| nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') | |
| if isinstance(m, nn.Conv1d): | |
| nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') | |
| elif isinstance(m, nn.BatchNorm1d): | |
| nn.init.constant_(m.weight, 1) | |
| nn.init.constant_(m.bias, 0) | |
| # initialize gru | |
| for layer_p in self.gru._all_weights: | |
| for p in layer_p: | |
| if 'weight' in p: | |
| nn.init.kaiming_normal_(self.gru.__getattr__(p), mode='fan_out', nonlinearity='relu') | |
| self.apply(_weights_init) | |
| def init_hidden(self, batch_size, use_gpu=True): | |
| if use_gpu: return torch.zeros(1, batch_size, 256).cuda() | |
| else: return torch.zeros(1, batch_size, 256) | |
| def forward(self, x, hidden): | |
| batch = x.size()[0] | |
| t_samples = torch.randint(self.seq_len/160-self.timestep, size=(1,)).long() # randomly pick time stamps | |
| # input sequence is N*C*L, e.g. 8*1*20480 | |
| z = self.encoder(x) | |
| # encoded sequence is N*C*L, e.g. 8*512*128 | |
| # reshape to N*L*C for GRU, e.g. 8*128*512 | |
| z = z.transpose(1,2) | |
| nce = 0 # average over timestep and batch | |
| encode_samples = torch.empty((self.timestep,batch,512)).float() # e.g. size 12*8*512 | |
| for i in np.arange(1, self.timestep+1): | |
| encode_samples[i-1] = z[:,t_samples+i,:].view(batch,512) # z_tk e.g. size 8*512 | |
| forward_seq = z[:,:t_samples+1,:] # e.g. size 8*100*512 | |
| output, hidden = self.gru(forward_seq, hidden) # output size e.g. 8*100*256 | |
| c_t = output[:,t_samples,:].view(batch, 256) # c_t e.g. size 8*256 | |
| pred = torch.empty((self.timestep,batch,512)).float() # e.g. size 12*8*512 | |
| for i in np.arange(0, self.timestep): | |
| linear = self.Wk[i] | |
| pred[i] = linear(c_t) # Wk*c_t e.g. size 8*512 | |
| for i in np.arange(0, self.timestep): | |
| total = torch.mm(encode_samples[i], torch.transpose(pred[i],0,1)) # e.g. size 8*8 | |
| correct = torch.sum(torch.eq(torch.argmax(self.softmax(total), dim=0), torch.arange(0, batch))) # correct is a tensor | |
| nce += torch.sum(torch.diag(self.lsoftmax(total))) # nce is a tensor | |
| nce /= -1.*batch*self.timestep | |
| accuracy = 1.*correct.item()/batch | |
| return accuracy, nce, hidden | |
| def predict(self, x, hidden): | |
| batch = x.size()[0] | |
| # input sequence is N*C*L, e.g. 8*1*20480 | |
| z = self.encoder(x) | |
| # encoded sequence is N*C*L, e.g. 8*512*128 | |
| # reshape to N*L*C for GRU, e.g. 8*128*512 | |
| z = z.transpose(1,2) | |
| output, hidden = self.gru(z, hidden) # output size e.g. 8*128*256 | |
| return output, hidden # return every frame | |
| #return output[:,-1,:], hidden # only return the last frame per utt |
[코드 line 9 - 25]
conv1d로 이루어진 encoder를 볼 수 있습니다.
[코드 line 26]
auto regressive모델로 gru를 씁니다.
[코드 line 27]
$f_k(x_{t+k}, c_t)$를 표현할 때 사용하는 $w_k$를 정의합니다.
[코드 line 31-46]
[31 - 38] 각각 Linear, Conv1d, BatchNorm1d 일 때 weights를 initialize 해줍니다.
[41 - 46] gru weights initialize
[코드 line 52 - 78]
[54] 임의의 time stamp를 결정합니다. 데이터로더를 보면 seq_len은 20480이라는 것을 알 수 있습니다. self.seq_len/160-self.timestep은 20480/160-12 이므로 116보다 작은 숫자 하나를 임의로 time stamp로 정한다는 것을 알 수 있습니다.
[56 - 59] 입력 x ➞ encoder를 구합니다.
[61 - 63] time stamp 별 데이터를 저장하기 위해 비어있는 텐서인 encode_samples를 만듭니다. 그 다음 전체 time step 만큼 총 12번의 반복을 통해 t_samples 크기만큼 encode_samples에 저장합니다. 이 encoded_samples은 미래를 예측할 때 사용할 $z_t$, $z_{t+1}$, ..., $z_{t+4}$라고 생각하면 됩니다.
[64 - 66] GRU에 넣을 $z_t$들을 구합니다. $z_t$, $z_{t-1}$, ..., $z_{t-3}$을 구한다고 생각하면 됩니다. 그 후 위 그림처럼 GRU에 넣고 $c_t$를 얻습니다.
[67 - 70] 전체 time step인 12만큼 $W_k$의 일부 * $c_t$를 통해 미래를 예측합니다.
[71 - 76] 미래 예측값 $z$들이 들어있는 encoded_samples과 위에서 구한 $W_k$의 일부 * $c_t$를 곱합니다. $f_k(x_{t+k}, c_t)$를 구하는 과정입니다. loss와 accuracy를 계산합니다.
모두의 연구소에서 진행하는
"함께 콘텐츠를 제작하는 콘텐츠 크리에이터 모임"
COCRE(코크리) 2기 회원으로 제작한 글입니다.
코크리란? 🐘
Reference
[그림 1] https://upload.wikimedia.org/wikipedia/commons/a/a0/Milky_Way_libya.jpg
[그림 2] https://ankeshanand.com/blog/2020/01/26/contrative-self-supervised-learning.html




{kind=link}